
Jest to mój pierwszy wpis w którym chciałbym przedstawić podstawy teoretyczne klasteryzacji dokumentów, tematu w ostatnim czasie mi bliskiemu.
Czym jest owa klasteryzacja dokumentów?
Aby ją opisać, pierw należy zdefiniować czym jest sama klasteryzacja.
Człowiek z natury ma skłonność do grupowania pewnych obiektów, rzeczy, faktów a także ludzi w większe klasy, grupy, kategorie lub zgodnie z tytułem nazwijmy je klastrami. Niech przykładem w tym artykule będą ludzie. Idąc ulicą i opisując kolejnych ludzi których mijamy moglibyśmy rzucać stwierdzeniami typu: starszy pan, następny starszy pan, ładna kobieta, brzydka kobieta, kuc i tak dalej. Moglibyśmy opisywać ich według ich wieku, wzrostu, koloru włosów, typu ubrania. Słowem znaleźlibyśmy wiele dziedzin w jakich moglibyśmy skatalogować ludzi.
Czym jest więc klasteryzacja?
Jeśliby przedstawić jej definicję, można stwierdzić, że klasteryzacja to proces takiego przydziału obiektów do grup do których skatalogowany obiekt należy do klastra do którego należy w większym stopniu niż do pozostałych. Wynikiem procesu klasteryzacji są obiekty wyższego rzędu, grupy, skupiające wewnątrz jednorodne grupy obiektów.
Co nam mówi ta definicja?
Cóż, mając zestaw zawierający pewną liczbę osób, którą chcemy poddać klasteryzacji, wynikiem byłyby grupy osób, które w ramach grupy łączyłaby wspólna cecha, taka która zostałaby użyta do oceny konkretnej osoby. Czy osoby opisane są poprzez zainteresowania? Proszę bardzo, wynikiem będą grupy ludzi o tych samych / podobnych zainteresowaniach.
Jak to wygląda w praktyce?
Klasteryzacja jest działaniem na punktach.
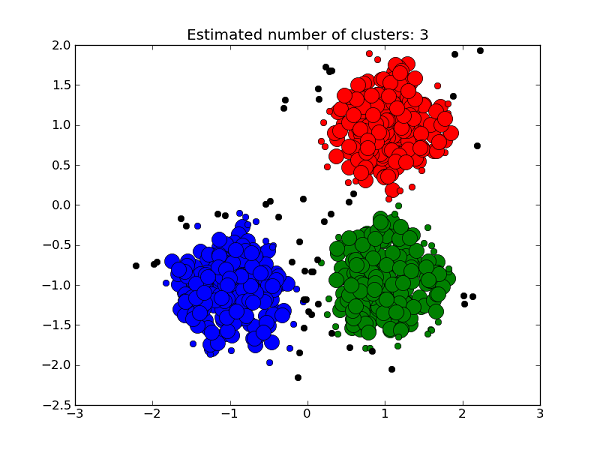
Dokładnie. Punkty grupowane są według odległości od siebie i według odległości przypisywane do klastrów. Przeważnie wyznaczany jest pewien punkt środkowy klastra, tzw. centroid, i wszystkie punkty przypisywane są do najbliższych centroidów, stąd każdy punkt w klastrze jest bliżej środka własnego klastra niż pozostałych środków.
Wróćmy do naszego przykładu z ludźmi. Jak niby mamy „sklasteryzować” ludzi, jeśli klasteryzacja działa tylko na punktach.
Da się ich jakoś zamienić?
Oczywiście, że się da. I ludzi i dokumenty tekstowe, które też punktami nie są a klasteryzowalne są. Proces odpowiedzialny za zamianę bardziej abstrakcyjnych na formę liczbową nazywany jest wektoryzacją. Wektory, czyli produkty tego procesu są macierzami o jednej kolumnie (a po transformacji o jednym wierszu). Każdy wiersz, czy może ściślej, każdy element wektora przyporządkowany jest jednej cesze. Wartość wektora w danym miejscu odpowiada zwyczajnie wadze, stopniu przynależności do tych cech.
Posłużę się znów moimi obiektami doświadczalnymi.
Załóżmy, że chcemy zamienić cechy określonej grupy ludzi na wektory. Niech będą to 3 cechy, które łatwo można określić liczbami, przyjmijmy, że pierwszy element wektora będzie oznaczał wiek, drugi wzrost, trzeci wagę.
[wiek, wzrost, waga]
I stwórzmy przykładowe wektory ludzi:
[18, 182, 85], [25, 164, 58], [35, 170, 89], [53, 179, 88].
Tak więc mamy punkty określające ludzi, a przynajmniej pewne ich cechy. Mając takich wektorów więcej można przeprowadzić klasteryzację wektorów i pogrupować ludzi według ich wagi, wzrostu i wieku.
Ale ale, nie tak szybko.
Wiedząc, że klasteryzacja działa w oparciu o odległości pomiędzy punktami, mając tak nieregularne dane, wpływ wzrostu lub wagi może mieć większy wpływ na wygląd zbioru niż wieku. Stąd dobrym pomysłem jest wpisywanie konkretnych wag do wektorów zamiast konkretnych wartości. Przykładowo mogą to być ilorazy wartości i predefiniowanej maksymalnej wartości. Innym pomysłem mogłoby być prawdopodobieństwo wynikające z rozkładu normalnego dla danej wartości.
Jak to wygląda w przypadku dokumentów?
Bardzo podobnie. Dokumenty zamieniane są na wektory a wartościami wektorów są konkretne wagi dla słów (i/lub) zwrotów znajdujących się w dokumencie wyliczanych na podstawie analizy całego zbioru dokumentów. Następnie tak utworzone wielowymiarowe punkty są klasteryzowane według odległości punktów od siebie. Opis algorytmów tworzących wektory dokumentów i klasteryzacji to już temat na inny wpis.